










Application Security Testing (AST) tools are part of a smart software security initiative (SSI). This category of tools includes Static Application Security Testing (SAST), Software Composition Analysis (SCA), Interactive Application Security Testing (IAST), and Dynamic Application Security Testing (DAST).
AST tools are designed to identify design flaws and coding errors that can result in security vulnerabilities prior to software being released.
Catching errors before deploying into a production environment can help reduce cost and improve quality. The earlier in the development process these vulnerabilities are found, the less impact on development time and cost.
This blog will focus on SAST tool effectiveness and discuss:
- How SAST scanners work
- True positives, false positives, and false negatives
- The gap in effectiveness as perceived by software engineering
- How a Security by Design approach can improve software development costs and outcomes
How Static Analysis Works
Static tools analyze source code or compiled applications to detect security vulnerabilities in the code written by internal developers.
They work by first building an Abstract Syntax Tree; a model of the application’s control flow, data flow, and variables. Once completed, the model can be queried to detect common security issues. Techniques include:
- Data flow analysis: Data flow analysis tracks how values are assigned, used, and propagated across different variables, functions, and modules. This helps identify potential security vulnerabilities related to input validation, data sanitization, and secure data handling.
- Control flow analysis: In control flow analysis, SAST tools examine the program’s structure and identify control flow constructs such as loops, conditionals, function calls, and exception handling. By analyzing these constructs, SAST solutions gain insights into how the program’s execution proceeds from one statement to another and how different program components interact.
- Symbolic analysis: This technique analyzes code by representing program variables and expressions symbolically rather than using concrete values. It focuses on exploring different execution paths and evaluating potential vulnerabilities without executing the code.
- Taint analysis: “Taint” is the concept of marking or flagging data that originates from potentially untrusted or unsafe sources such as users. From a security perspective, tainted data should be validated or “sanitized” before reaching vulnerable functions. By following the propagation of tainted data and applying taint analysis rules, a SAST tool can identify potential security vulnerabilities in the code. For example, it can flag instances where tainted data is used in database queries without proper sanitization or where tainted data is directly embedded in dynamically generated HTML without proper encoding.
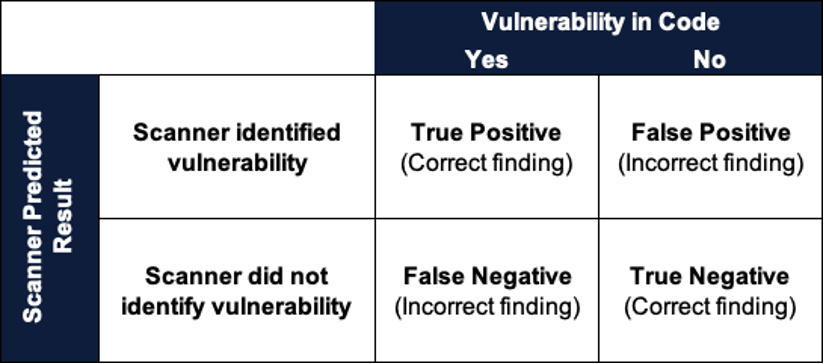
Based on a series of logical security tests, a scanner will produce a result to indicate whether the test fails (i.e., whether a vulnerability exists in the code).
This may or may not correspond to the truth. The goal of a scanner is to minimize errors of omission (not correctly identifying vulnerabilities) and incorrect alerts. In short, we have four possibilities:
- True Positive: The number of true vulnerabilities correctly identified by the SAST tool. These are instances where the tool correctly detects a security issue that indeed exists in the code.
- False Positive: The number of instances where the SAST tool incorrectly identifies a non-existent vulnerability or reports a false positive. These are cases where the tool flags code segments as vulnerabilities, but upon manual inspection, they are determined to be safe.
- True Negative: The number of non-vulnerable code segments correctly identified as safe by the SAST tool. These are instances where the tool accurately recognizes that the code is secure.
- False Negative: The number of vulnerabilities missed by the SAST tool, where it fails to detect actual security issues. These are cases where the tool overlooks security vulnerabilities that exist in the code.
Why SAST Will Always Generate False Positives and False Negatives
No tool is perfect, including SAST tools. Static analysis of software is difficult. Vendors have spent hundreds of millions of dollars in research to improve results with varying degrees of success. The National Institute of Standards and Technology (NIST) has conducted several studies on the effectiveness of SAST tools. NIST found wide variations in the false positive rates produced by different SAST tools. The fifth study in 2018 found false positive rates between 3 percent and 48 percent for ten SAST tools analyzed.
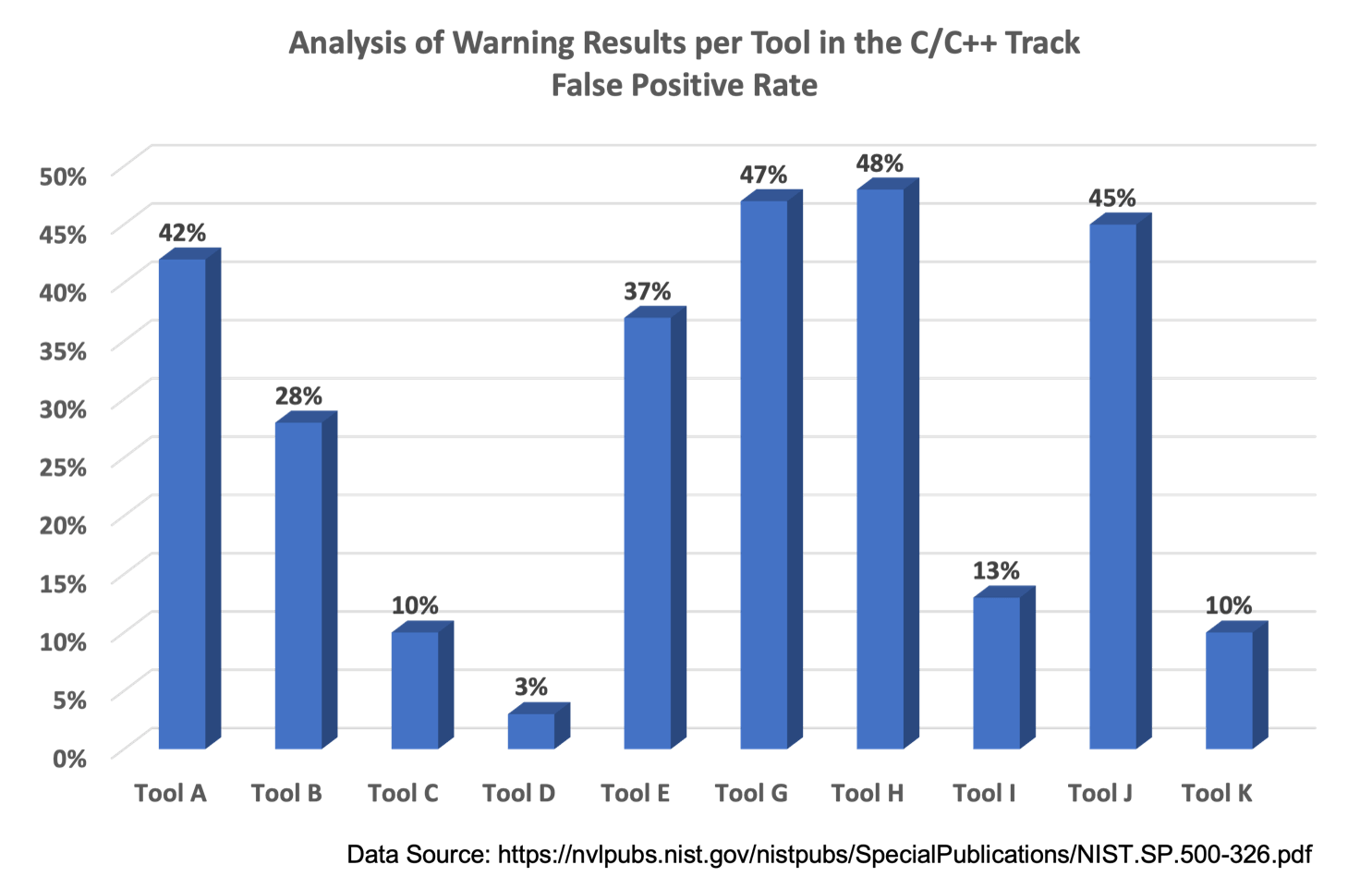
Note that a three percent false positive rate does not necessarily mean that 97 percent of the results were accurate and useful. That particular tool had a true positive rate for security issues of zero percent! Most of its findings (73 percent) were classified as “insignificant”: findings related to style rules or low priority issues that pose acceptable risk. The remaining findings were a true positive rate for quality issues of 23 percent.
False positives slow down development and can increase friction between security and engineering. Research by GrammaTech found that triaging a single finding — irrespective of category — requires 10 minutes on average. In other words, triaging only 240 issues requires 40 hours — a workweek — of effort.
While everyone wants to address True Positives, pushback is inevitable when these make up barely half of the issues generated by a scanner.
There are several reasons SAST tools will inevitably produce false positives and not detect true positives. These include technical limitations, design decisions by vendors, and compiler technology.
The Halting Problem
The halting problem is a fundamental concept in computer science and mathematics, first introduced by Alan Turing in 1936. It refers to the question of whether a general algorithm can determine, for any given program and input, whether the program will eventually halt (terminate) or continue running indefinitely (loop forever).
In a perfect world, we are able to execute a program from the start state through the termination (or Halt) stage. As software becomes more complex, this becomes non-deterministic. The assumption made by scanners, however, is that we can execute code from start to finish predictably.
Some vulnerabilities cannot be identified through automation
Common Weakness Enumeration (CWE) is a community-developed list of software and hardware weakness types that can be present in software applications. SAST tools can help identify many common weaknesses and vulnerabilities in code but are not able to identify all CWE.
SAST tools are designed to detect specific patterns or signatures in the code that are associated with known vulnerabilities. These tools can be effective at finding issues like SQL injection, cross-site scripting, buffer overflows, or insecure cryptographic implementations. However, they may not be able to detect more complex or subtle vulnerabilities that require a deeper understanding of the code’s behavior, logic, or business rules.
These types of issues often require a combination of manual code review, security architecture analysis, or other techniques that involve human expertise and a deeper understanding of the application’s context.
SEI CERT Oracle Coding Standard for Java provides several examples where “Automated detection is infeasible in the general case.” :
| Rule | Description |
| NUM03-J | Use integer types that can fully represent the possible range of unsigned data |
| NUM08-J | Check floating-point inputs for exceptional values |
| OBJ02-J | Preserve dependencies in subclasses when changing superclasses |
| OBJ05-J | Do not return references to private mutable class members |
| OBJ11-J | Be wary of letting constructors throw exceptions |
| FIO05-J | Do not expose buffers created using the wrap() or duplicate() methods to untrusted code |
| FIO06-J | Do not create multiple buffered wrappers on a single byte or character stream |
| FIO12-J | Provide methods to read and write little-endian data |
| SER02-J | Sign then seal objects before sending them outside a trust boundary |
| SEC00-J | Do not allow privileged blocks to leak sensitive information across a trust boundary |
| SEC04-J | Protect sensitive operations with security manager checks |
| SEC06-J | Do not rely on the default automatic signature verification provided by URLClassLoader and java.util.jar |
| ENV00-J | Do not sign code that performs only unprivileged operations |
| ENV01-J | Place all security-sensitive code in a single JAR and sign and seal it |
Scanners are typically optimized for a certain class of vulnerabilities.
Not all scanners are created to catch the same category of vulnerabilities. Each vendor makes different engineering decisions when attempting to optimize their tool. Some are focused on the syntax level while others perform a detailed model analysis to try and derive data and flow information. Because of this, some organizations have opted to use multiple scanners to try and fill the gaps. Even when using multiple tools, however, issues can be missed.
One study demonstrates the results of detecting a buffer overflow error in C++ code. As one can see, the tools missed between 56.5 percent and 68.3 percent of the test cases. Even when using all three scanners together less more than half of the buffer overflow instances were missed.
| SAST Tool(s) Used | # Identified Bugs | False Negative Rate |
| SAST A | 19 | 68.3% |
| SAST B | 32 | 68.0% |
| SAST C | 10 | 56.5% |
| SAST A + SAST B | 42 | 58.0% |
| SAST B + SAST C | 39 | 61.0% |
| SAST A + SAST C | 26 | 59.4% |
| SAST A + SAST B + SAST C | 47 | 53.0% |
Scanners do not understand intent
Because scanners rely on a predefined set of rules, they cannot interpret a developer’s intent. Understanding the intent of the code often requires a more dynamic analysis or a combination of different techniques, such as manual code review, security architecture analysis, or penetration testing. These approaches involve human expertise and can provide a deeper understanding of the application’s behavior, potential attack vectors, and overall security posture.
Compiler optimization can inject security vulnerabilities
Most SAST tools analyze source code during the development phase. Compiling code can introduce security vulnerabilities even though a scanner did not find an issue. One research team identified three classes of security weaknesses introduced by compiler optimizations:
- information leaks through persistent state
- elimination of security-relevant code due to undefined behavior
- introduction of side channels
They produced the following example where a compiler can introduce security vulnerabilities.
crypt(){
key = 0xC0DE; // read key
… // work with the secure key key = 0x0; // scrub
memory
}
Here the developer practiced good security by scrubbing the key from memory. However, to improve software performance, the compiler may view the last instruction as unnecessary and ignore it, leaving the key available in memory.
Compensating for SAST Limitations
While SAST tools clearly have a useful role in identifying application security errors, they cannot be the only activity used to identify security vulnerabilities. As shown, there are many situations where scanners will miss known vulnerabilities and target non-existing ones. The key to filling this gap is recognizing the limitations of security testing and working proactively to minimize design flaws and coding errors.
Security by Design
While security testing is a best practice, it should not be an organization’s only security activity. Using scanners as a primary way of building security into applications is inefficient, as they simply scanners find vulnerabilities after they have been produced. A Security by Design philosophy ensures that systems are built with security in mind from the very beginning of the development process, well before testing is possible.
Security by Design Starts with Secure Development Requirements
Secure development requirements are measures that must be implemented to ensure the confidentiality, integrity, and availability of software systems. Creating security requirements in the design phase of the SDLC, well before coding begins. This helps development, security, and operations build secure code before testing begins.
Secure development requirements identify threats to an application. While there are some best practices like input validation that are common to all development projects, others will be dependent on the technology stack, and applicable regulatory, customer, or internal requirements for each project. These can include threats inherent to the development language, software frameworks, and common attack patterns as well as threats for specific deployment environments such as AWS, Microsoft Azure, and Google Cloud Platform.
Manually creating secure development requirements can challenge even the most well-resourced teams. Manual processes take time. Few organizations can wait days or weeks to generate secure coding requirements.
SD Elements Automates Secure Development Requirements
SD Elements is a developer-centric platform for automating secure development requirements and building secure and compliant software by design. Based on a brief survey, SD Elements identifies applicable regulatory standards and threats to an applications technology stack and deployment environment. It then translates those threats into actionable security controls and assigns them to development, QA, security, and operations through the teams’ existing systems such as Jira.
By automating secure development requirements, organizations are able to achieve:
- Scalability: Manually creating secure coding requirements for each new project demands time and effort from scarce security and development resources. SD Elements generates controls and countermeasures in minutes, not weeks.
- Consistency: The output from manual threat models reflects the knowledge and biases of those participating in the exercise. As team members change identified threats and controls will also change. SD Elements provides consistent, pre-approved controls and countermeasures.
- Traceability: While many engineering teams will have secure development policies, few have ways to validate that each policy is followed. This lack of traceability makes it impossible to understand the security posture of an application or portfolio. SD Elements provides a centralized platform and integration with testing tools to allow near real-time information on the status of controls.
- Regulatory compliance: Today’s regulatory environment changes rapidly. Keeping track of overlapping requirements is difficult and the consequences of non-compliance can be damaging to an organization. Security Compass’s content library is curated by a team of security professionals tracking dozens of regulatory standards and frameworks to keep SD Elements up to date.
- Continuous developer training: SD Elements full suite of on-demand, secure development training keeps security top of mind throughout the development lifecycle. Courses are role-based and cover topics from security awareness courses that educate employees on good cyber hygiene practices to in-depth reviews of threats and vulnerabilities specific to an experienced developer’s technology stack.
Compliant and Secure Software by Design
Security testing tools like static analysis are an important part of any secure software program. To build more secure software faster, however, a more proactive strategy is needed.
SD Elements enables teams to identify risks to software and prescribe security controls as part of the normal development process. The result is more secure software with fewer delays.
To learn more about the problem of false negatives, you won’t want to miss our deep dive into code scanners.